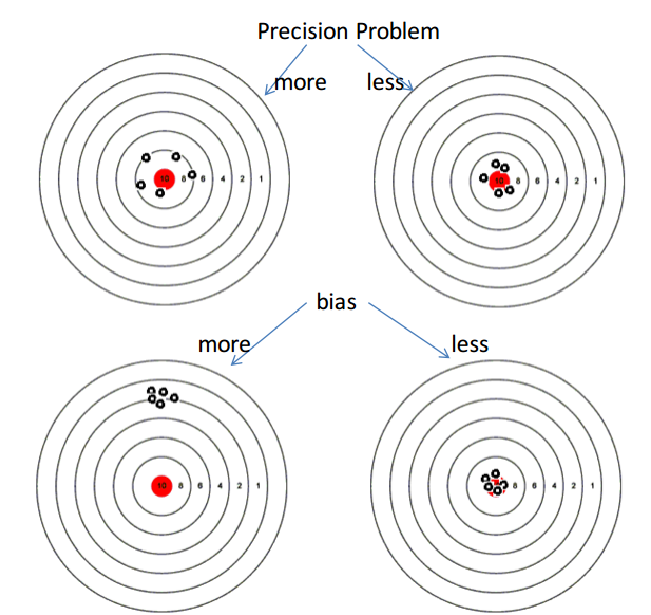
A common challenge of working with small sample sizes is determining proper bias correction methods when evaluating a given set of data. Oftentimes, statisticians depend on large sample sizes to naturally correct for any bias. Small sample sizes, by contrast, require innovations like Firth’s famous bias correction method.
Recently, Cytel statisticians Ashwini Joshi and Sumit Singh gave a talk entitled “How to Reduce Bias in the Estimates of Count Data Regression.” Using a number of case studies and simple to use LogXact PROC software, they demonstrate the ease with which bias correction can be implemented for small sample clinical data.
The slides from Ashwini and Sumit's talk are accessible using the link below.

Abstract: We consider solutions employing Firth's bias correction method when confronted with especially small sample clinical data. We also examine how the method can mitigate degrees of "quasi-separation" and also performance when applied to large datasets.
[1] Firth, David. "Bias reduction of maximum likelihood estimates." Biometrika80.1 (1993): 27-38.