September 15, 2020
In clinical trials with small or sparse data, statistical methods meant for large sample sizes may not be helpful to...
Read article
September 18, 2017
By Ashwini Joshi For small sample data or rare events data, exact non-parametric tests perform better than asymptotic...
Read article
October 29, 2015
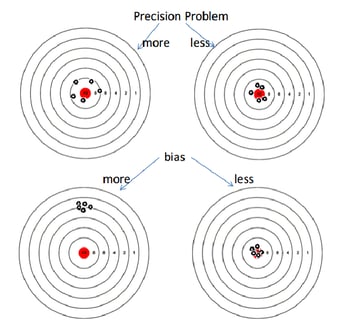
A common challenge of working with small sample sizes is determining proper bias correction methods when evaluating a...
Read article
October 19, 2015
It is often necessary to pool safety data from late phase studies, in preparation for regulatory submission. Some of...
Read article
June 25, 2015
When conducting a clinical trial with small or sparse data sets, statistical methods meant for large sample sizes may...
Read article