

How do you envision the future of data submission?
Last week, I had the privilege of presenting the topic “Standards and Open-Source Hand-in-Hand: Leveraging Automation to Expedite Drug Market Request Review Process” at PharmaSUG-China in Nanjing. It was an honor to be invited as a keynote speaker to this event.
When I was approached to deliver a keynote speech, I pondered over the possible subjects. Given my background, I offered a range of options, each tailored to my expertise. And the obvious answer was “Something aligned with this year’s conference theme, something around this and that, but most important, we hope to hear the topic presented in a creative way so that people can get inspired by your presentation.” That’s usually what a keynote speaker should do.
The journey to prepare this speech commenced approximately three months ago. At that time, I was finishing reading the book AI 2041, a collaborative work by Kai-Fu Lee, a visionary technologist, and Chen Qiufan, a distinguished science fiction writer.
 “AI 2041,” Kai-Fu Lee, Chen Qiufan, 2021
“AI 2041,” Kai-Fu Lee, Chen Qiufan, 2021
Their approach to the book was truly ingenious. By weaving together ten distinct stories set in the year 2041 across diverse global locations such as Africa, Asia, and even a post-COVID-19 Shanghai, they tried to imagine how Artificial Intelligence (AI) would change our world within twenty years; at the end of each story, they introduced, in a “human readable” fashion (we could say a sort of AI for dummies), different AI or AI-like concepts or technologies you can see summarized below:

If we want to translate this into our world, into our industry, I posed the question, “How do you envision data submission in 2041?”
In the presentation, I imagined some science fiction scenario, such as an AI preparing the eCTD, submitting, and handling the discussion with the HA reviewer, a reviewer having some support from an AI in performing the review, assuring that the sponsor has provided everything needed to confirm safety and efficacy of the product, including checking results and quality of data packages we provide.
I did not want to go further, so I went back to the present to consider and discuss what are we doing now to target 2041, by illustrating new standards initiatives and what open sources initiatives we are running today, and what technologies are being developed through new data standards and open-source initiatives.
Open source represents a paradigm shift in our industry.
Let me clarify. Embracing open-source initiatives does not imply the obsolescence of traditional tools like SAS. Rather, it signifies a transition toward collaboration. The core objective of our industry remains the development and, hopefully, successful marketing of medical products, such as drugs and devices. In the pharmaceutical sector, revenue generation isn’t centered around software. Thus, it is of diminishing concern if sponsors like Roche share their valuable R library with other companies, a library that may have cost millions of dollars and years of development. Sharing now presents an opportunity for companies like Roche, as the act of sharing guarantees a return on investment. This is because other companies can enhance the package, address bugs, and introduce new features, resulting in mutual benefits.
Open source is a change already occurring based on experience shared at conferences I regularly attend; see, for example, the following chart showing the percentage of technical presentations containing open-source topics (this is based on my own assessment of titles and abstracts of the last eight years of conferences).
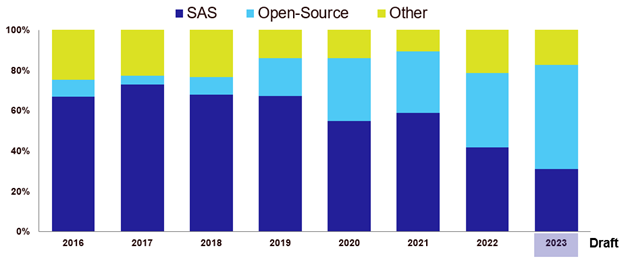 Percent of Open-Source Topics vs. SAS in Technical Presentations at PHUSE-EU, 2016–2023
Percent of Open-Source Topics vs. SAS in Technical Presentations at PHUSE-EU, 2016–2023
There are already organizations and individuals attempting to step into the future. The event itself in China had plenty of presentations discussing the potential of AI, including the final keynote speech by Helen Wu from MSD titled “How ChatGPT will affect programmers’ daily work and how we can better prepare for change.”
Some attempts, numerous examples, and a wealth of user experiences and proof of concepts exist. Health Authorities (HA), such as the FDA, are also engaging initiatives aimed at improving the way we do data submission.1 However, even with all these efforts, we still encounter challenges in submitting well-constructed data packages to the HA, as indicated by feedback shared during public events.2 Given the HA’s emphasis on quality, establishing credibility with reviewers is crucial.3 Quality can be compromised by seemingly minor mistakes or issues that might initially appear irrelevant. Such factors could significantly impact the outcome of your submission and the success of your drug approval process if your data package fails to meet the predefined criteria, as discussed by Travis Collopy at PharmaSUG-China 2019.4
 Travis Collopy – Keynote speaker at PharmaSUG China 2019
Travis Collopy – Keynote speaker at PharmaSUG China 2019
Numerous obstacles currently impede the realization of the 2041 vision. Among these obstacles are the lack of interoperability and the use of outdated data transfer formats (e.g., SAS XPT). Additionally, there’s a growing need for more analytical approaches, such as data visualization.
Thankfully, there are ongoing open-source initiatives and the development of new standards that hold the potential to address these issues and enhance the process of preparing data submission packages. In the latter part of this post, I introduce the initiatives that I believe are pivotal for achieving the vision spanning from 2023 to 2041.

Interested in learning more about data submission? Download our complimentary new ebook, The Good Data Doctor on Data Submission and Data Integration:

Notes
1. “Reimagining Regulatory Data Submissions Modernizing Partnering and Exploring How Regulatory Data Could Be Shared with HAs,” J. Galvez, PHUSE-US 2023.
2. “PMDA Update,” Yuki Ando, CDISC EU Interchange 2023.
3. “How to Ensure Quality in Data Submission?” Angelo Tinazzi, PharmaSUG-China 2019.
4. “Evolution of Data Standards from Practical Perspective,” Travis Collopy, PharmaSUG-China 2019.
Read more from Perspectives on Enquiry and Evidence:
Sorry no results please clear the filters and try again

The Evolution of Open-Source Initiatives and New Standards Development for the Data Submission of the Future

New Ebook: “The Good Data Doctor on Data Submission and Data Integration”
It’s Time to Move, Time to Move to Define-XML 2.1