October 23, 2018
Cytel data scientists apply advanced statistical techniques including predictive modeling of biological processes and...
Read article
July 27, 2018
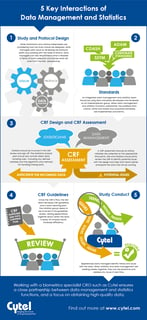
In this blog, we share a new infographic based on this popular blog post illustrating some of the critical interactions...
Read article
June 14, 2018
In this blog, Paul Fardy, Executive Director of Data Management at Cytel shares his thoughts on how the data manager...
Read article
April 25, 2018
Data management is an essential building block for successful Immuno-Oncology (I-O) trials. At the Immuno-Oncology...
Read article
January 23, 2018
News Medical interviewed Dr. Rajat Mukherjee, Statistician, and Director of Data Science at Cytel to investigate the...
Read article
January 15, 2018
The problem of feature selection The explosion in the availability of big data has made complex prediction models a...
Read article
July 28, 2016
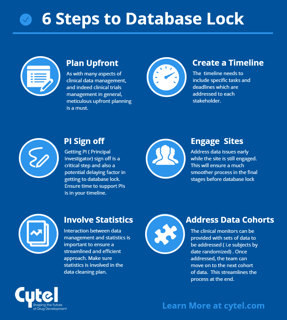
To close a clinical database right the first time you have to begin with study start-up. Clearly, you can’t close a...
Read article
July 25, 2016
Statistical programmers are in high demand within the biopharmaceutical industry, and within the dynamic world of...
Read article
May 19, 2016
The explosion in healthcare information and “big data “has been one of the most written about topics in the last few...
Read article