
Health professionals and policy makers want to make healthcare decisions based on the relevant research evidence. The questions in clinical research are typically studied more than once independently by different researchers. Literature review is used for summarizing the results of these studies and strengthening the evidence. Systematic review is a type of literature review that collects and critically analyzes multiple research studies or papers that answer the same question. If the results of these multiple studies are diverse and conflicting then the clinical decision-making becomes difficult. To overcome this problem meta-analysis is used. Meta-analysis is a statistical procedure for combining the results of studies that are included in systematic review. While meta-analysis is a powerful technique, it may give misleading results due to issues like improper selection of studies, publication bias, and heterogeneity among studies. In this blog, we will focus on the problem of heterogeneity.
 As the goal of meta-analysis is to combine individual studies giving more precise estimate of the treatment effect, there needs to be a check that the effect estimates from the individual studies are similar enough so that a combined estimate will be meaningful. However, the individual estimates of treatment effect will vary by chance. The question is whether there is more variation than expected by chance alone. When excessive variation occurs, it is called heterogeneity. There are two types of heterogeneity - namely clinical heterogeneity and statistical heterogeneity.
As the goal of meta-analysis is to combine individual studies giving more precise estimate of the treatment effect, there needs to be a check that the effect estimates from the individual studies are similar enough so that a combined estimate will be meaningful. However, the individual estimates of treatment effect will vary by chance. The question is whether there is more variation than expected by chance alone. When excessive variation occurs, it is called heterogeneity. There are two types of heterogeneity - namely clinical heterogeneity and statistical heterogeneity.
Clinical heterogeneity occurs due to differences in the patients enrolled in the studies, different study settings, etc. Sometimes there can be slight differences in study design or quality of individual studies. The interventions, even if they are the same drug can be given differently. Combining such studies is clinically meaningless. Judgments about whether clinical heterogeneity is present or not are qualitative. They do not require any complex calculations- rather; one can make the decision using clinical knowledge.
Statistical heterogeneity comes into the picture when individual trials have results that are not consistent with each other. Some studies may show benefit due to the treatment and some may show harm! Even if all the studies show benefit or harm, the effect size could be different. In this case, a statistical evaluation is needed to ascertain if statistical heterogeneity is present. Heterogeneity can be assessed using the eyeball test (graphical method) or more formally with statistical tests, such as the Cochran’s Q test or index of heterogeneity I2 (I-squared).
The eyeball test involves getting a sense of data by looking at the forest plot. A forest plot is a graphical display of the effects of individual studies along with their overall effect. E.g. see the following forest plot:
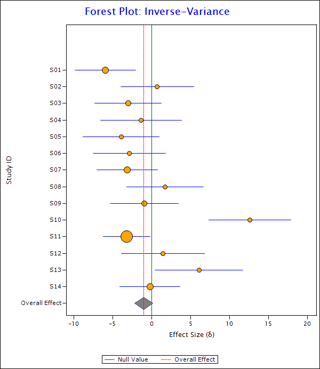
In this plot, the orange circles show the effect sizes of individual studies and the blue horizontal lines show corresponding confidence intervals. Radius of the circle is directly proportional to the weight assigned to the study. The elongated diamond at the bottom represents overall effect and its confidence interval. The red vertical line passing through the vertices of the diamond is the line of overall effect. The green vertical line shows the null effect line.
Now compare the two plots below:
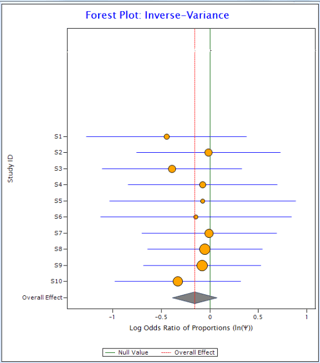
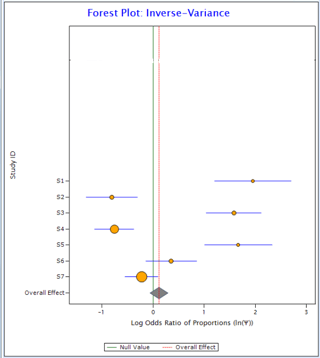
Figure 1 Figure 2
In Figure 1, all the horizontal lines representing individual studies are passing through the overall effect (red vertical line). It suggests that individual studies are homogeneous. On the other hand, in Figure 2, only one individual study is passing through overall effect suggesting the existence of heterogeneity in the data.
The most commonly used statistical test to test the presence of heterogeneity is Cochran’s Q test. The null hypothesis of this test states that all the studies demonstrate the same treatment effect, i. e. they are homogeneous. High p-values (generally, p-value > 0.05) suggest homogeneity or lack of heterogeneity. However, when the number of studies included in the meta-analysis is small, this test is often not useful due to its low power.
Of course, quantifying heterogeneity is more useful than just detecting its presence. I2 is a commonly used statistic to quantify heterogeneity. It is defined as the percentage of variation across studies due to heterogeneity rather than chance. I2 ranges from 0 to 100. Generally, I2 is interpreted as follows:
• I2 = 0 suggests no heterogeneity.
• 0 <I2< 25% suggests low heterogeneity.
• 25% < I2 <75% suggests moderate heterogeneity.
• I2 > 75% suggests high heterogeneity.
For the data in Figure 1, I2 comes out as 0 and for the data in Figure 2 it is 94%.
To deal with moderate heterogeneity in the data, it is recommended to use a random effects model for combining the estimates. In a random effects model, it is assumed that the true effect is not the same in all studies. It also assumes that the studies were drawn from different populations. Overall effect estimated by the random effects model represents the mean of the distribution of the true effect.
Cytel is developing a tool for meta-analysis which provides overall effect of studies of interest using fixed and random models, inference for heterogeneity, and tests of publication bias. In the case of studies having rare events, meta-analysis using exact computations can be done using the tool.
To learn more about Cytel's custom software solutions, click the button below.

Cytel is excited to present the webinar below on recent work in QPP Custom Software. Click to watch webinar.

About the author
 Anwaya Nirphirake is a Software Enthusiast at Cytel working as a software tester. She has 1.5 years of experience working in the areas of software development. and holds M.A. in Statistics, from Savitribai Phule Pune University. Her interests include analysis of data using R programming. Outside of work, she enjoys reading and swimming.
Anwaya Nirphirake is a Software Enthusiast at Cytel working as a software tester. She has 1.5 years of experience working in the areas of software development. and holds M.A. in Statistics, from Savitribai Phule Pune University. Her interests include analysis of data using R programming. Outside of work, she enjoys reading and swimming.
Editor's note : This blog is based on a talk presented at ConSPIC 2017 by Anwaya Nirphirake