

R is on the rise in biopharma, and as we have previously discussed on the blog, it is now time for SAS programmers to get up to speedwith this popular and powerful programming language. Indeed, one of the advantages of R is its ability to integrate with other languages like C, C++, Python and SAS. Its strong graphical capabilities allow output in PDF, JPG, PNG, and SVG formats and table outputs for LaTeX and HTML. Importantly, as an open source resource, there is a strong community around R and extensive support for users in the form of forums like R-bloggers, StackOverflow and GitHub Repository
In this blog, we’ll provide an overview of R basic structures for programmers.
Data types
R provides support for different kinds of data of the following types:
Logical – e.g., log.var <- c(TRUE, TRUE, FALSE)
Integer – e.g., int.var <- c(1L, 6L, 10L); L stands for “long integer”
Double (also called numeric) – e.g., dbl.var <- c(1, 2.5, 3.6)
Character – e.g., chr.var <- c(“hello”, “d”, “a”)
Factors - These are categorical variables.
e.g., fact.var <- factor(c("red", "green", "blue"))
These data types have analogues in other common programming languages.
Data Structures
Factor Variables
Factor variables are a structure specific to R- there is not a direct comparison available in SAS. However languages like C and C++ do have enum variables that are somewhat similar to the factor variables in R.
In this structure, variable values are treated as factors – in other words, a fixed list of values which the variable can take. A great deal of data used in statistics has fixed values which can thus be coded as factors in the R program, and used to store either nominal or ordinal variable types.

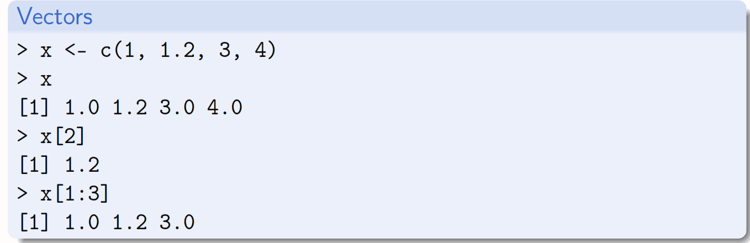
Vectors
Another data structure of note provided in R are vectors. One important aspect of vectors is that all elements must be of the same type. Common operations on vectors include:
- typeof()
- length()
- is function e.g., is.character(), is.double(), is.integer()
Matrices
A matrix is a collection of elements in a two-dimensional rectangular format as in the example below.

Data frames
This is one of the most important structures and very often used by statisticians and statistical programmers when analyzing data. A data frame is a data table with multiple columns. The columns could be of different data types, which is the prime difference between data frame and matrix.

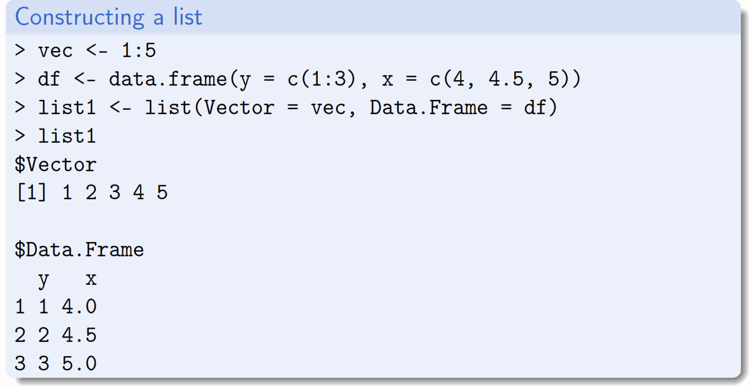
Lists
A list is a very useful structure which allows the programmer to put different types of structures together in one output- for example you could compile several data frames, or a combination of structures such as one matrix, one data frame etc.
In a follow up blog, we'll go on to overview other aspects of basic syntax and variables. Sign up for blog notifications and get updates direct to your inbox.

Want to learn more? Further related reading is below:
The Rise of R- is it time for SAS programmers to get up to speed?
The evolving role of the modern statistical programmer
With many thanks to Cytel's Namrata Deshpande and Imran Hossein.